
The 4 Layer Agent Evaluation Framework
The hardest part in building AI apps is not models. Its Evaluation

Traditional testing gave us false confidence.
Unit tests passed
Integration tests passed
Code review approved
𝗕𝘂𝘁 𝗽𝗿𝗼𝗱𝘂𝗰𝘁𝗶𝗼𝗻 𝗳𝗮𝗶𝗹𝗲𝗱
𝗪𝗵𝘆 𝗔𝗜 𝗲𝘃𝗮𝗹𝘂𝗮𝘁𝗶𝗼𝗻 𝗶𝘀 𝗱𝗶𝗳𝗳𝗲𝗿𝗲𝗻𝘁:
AI agents are non-deterministic. Standard testing doesn’t work.
You need to validate what traditional testing ignores:
→ Semantic correctness (Does it understand intent?)
→ Reasoning correctness (Does it think logically?)
𝗙𝗼𝗿 𝘀𝘁𝗮𝗿𝘁𝘂𝗽𝘀, 𝗿𝗲𝗹𝗶𝗮𝗯𝗶𝗹𝗶𝘁𝘆 = 𝘀𝘂𝗿𝘃𝗶𝘃𝗮𝗹.
No second chances. Every bug erodes trust you can’t rebuild.
𝗪𝗵𝗮𝘁 𝗜 𝗱𝗶𝘀𝗰𝗼𝘃𝗲𝗿𝗲𝗱:
Issues in one evaluation stage cascaded downstream → untraceable production failures.
The fix? Compartmentalize. Test tools separately from reasoning, reasoning separately from outputs, outputs separately from metrics.
Last week, Google’s “𝗦𝘁𝗮𝗿𝘁𝘂𝗽 𝗧𝗲𝗰𝗵𝗻𝗶𝗰𝗮𝗹 𝗚𝘂𝗶𝗱𝗲: 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁𝘀” validated exactly what I learned the expensive way. The guide has the multi-evaluation framework for evaluating AI agents.
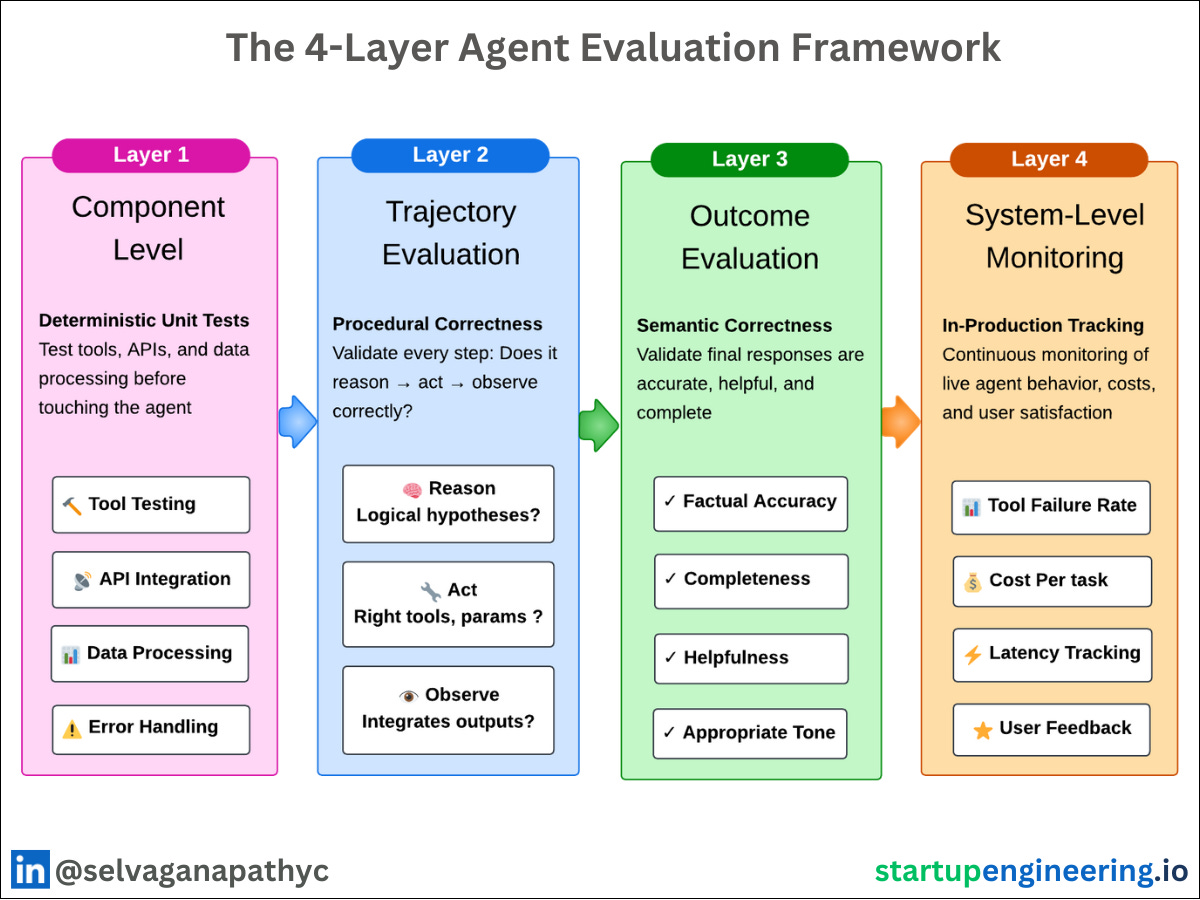
𝗧𝗵𝗲 𝟰-𝗟𝗮𝘆𝗲𝗿 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸:
𝗟𝗮𝘆𝗲𝗿 𝟭: Component Testing Deterministic unit tests for tools and APIs → Catches 90% of basic failures → Takes 2 days to set up. Don’t skip it.
𝗟𝗮𝘆𝗲𝗿 𝟮: Trajectory Evaluation ⚡ 𝗠𝗢𝗦𝗧 𝗖𝗥𝗜𝗧𝗜𝗖𝗔𝗟 Validate reasoning path, not just outputs → Does it reason correctly? → Right tools with right parameters? → Does it learn from outputs?
𝗟𝗮𝘆𝗲𝗿 𝟯: Outcome Evaluation What users actually see: → Factual accuracy → Helpfulness → Completeness
𝗟𝗮𝘆𝗲𝗿 𝟰: System Monitoring Track real-world performance: → Tool failure rates → Cost per conversation → User feedback scores
𝗪𝗵𝗮𝘁 𝗜 𝗹𝗲𝗮𝗿𝗻𝗲𝗱:
Issues cascade. Compartmentalize testing—saved weeks of debugging.
Trajectory validation cut debugging time 95%.
Cost monitoring isn’t optional for startups.
𝗪𝗵𝗮𝘁 𝗜’𝗱 𝗱𝗼 𝗱𝗶𝗳𝗳𝗲𝗿𝗲𝗻𝘁𝗹𝘆:
Don’t: Ship based on “it looks good in demos” Do: Build evaluation into CI/CD from day one
Don’t: Test only final outputs Do: Validate every reasoning step
Don’t: Skip component testing Do: Start with Layer 1. Always.
P.S: Google’s “Startup Technical Guide: AI Agents” link in comments.