
LLM integration to our application turned debugging into a nightmare. Here’s how we fixed it in 5 days with zero new tools.
Startup Engineering Principle : Choose Simple over Perfect Solution

The Problem:
A single user request triggers 200+ LLM calls. Which one failed? Where did context break? Our MTTR became as high as 7 hours. As a startup, we cannot afford to have our reputation at stake.
The Startup Dilemma:
Everyone suggested: LangSmith, LangFuse, Helicone.
Evaluating tools = 2–3 weeks
Every new tool = learning curve + cost + vendor management
We don’t even know what we need yet
First-Principles Questions:
What exactly do we need to debug? Input sent, response received, post-processing results, and relationships between 200+ calls.
The insight: Not a logging problem. It’s a tracing problem. Each LLM call is stateless. Our application maintains context. Same applies to observability.
The Solution:
We already had Grafana Loki, Tempo, and OpenTelemetry.
The breakthrough: Connect all LLM calls under one parent span.
Architecture :
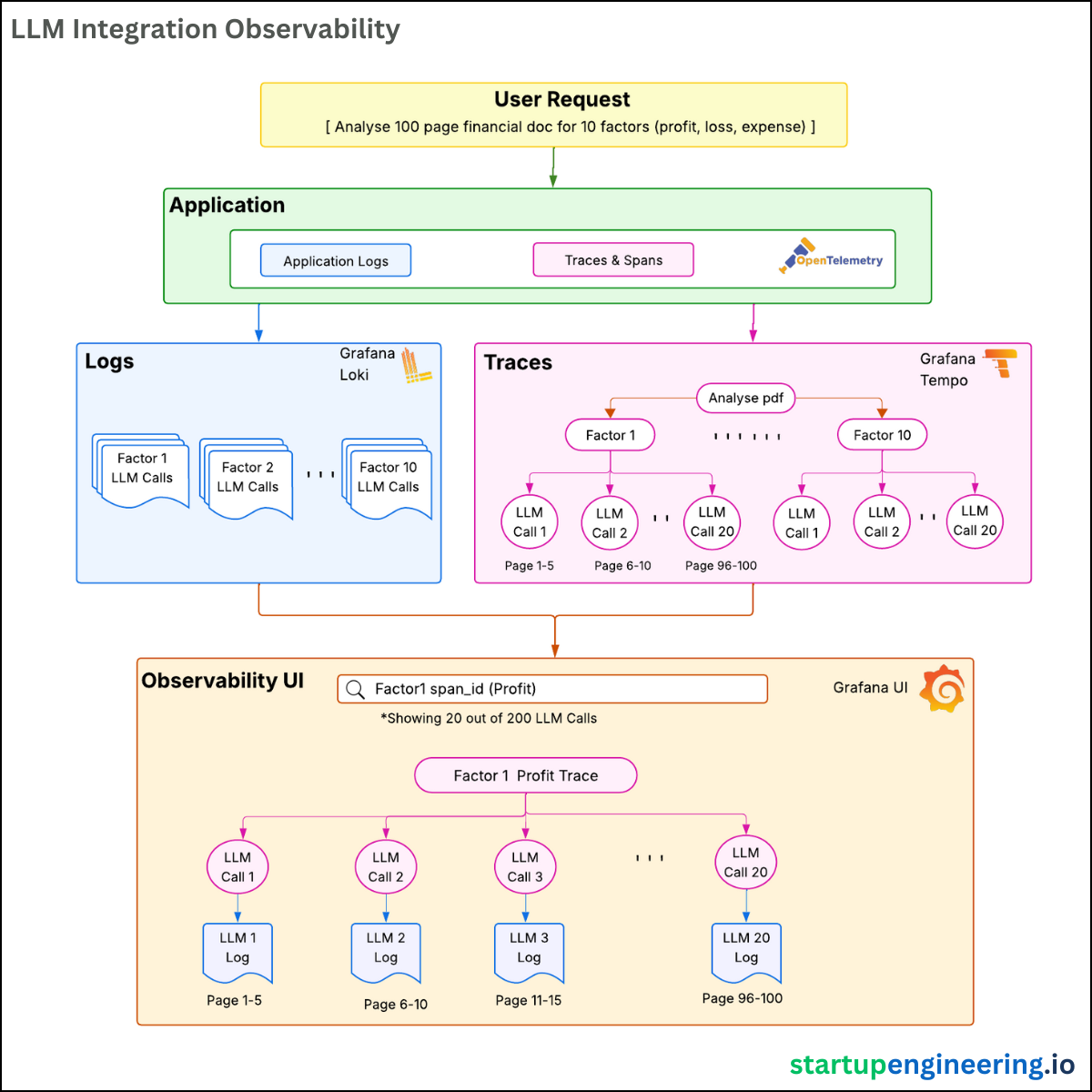
Application Layer
OpenTelemetry emits logs and traces.Logs (Grafana Loki)
Captures each LLM interaction:trace_id & span_id
Message sent & response received
Traces (Grafana Tempo)
Parent span connects all related calls:
“Analyze PDF” → Factor 1 (Profit) → Factor 10
Each factor → LLM Call 1… Call 20
Shows serial vs parallel execution, timing.
Observability UI (Grafana)
Query by span_id → Complete journey with all logs.
The Results:
MTTR: 7 hours → 30 minutes
Timeline: 5 days (2 design + 2 dev + 1 infra)
Cost: $0 in new tools
Complexity: Zero new vendors
Key Design Decisions:
Why Traces Over Logs?
Logs show events. Traces show relationships. For 200+ interconnected calls, relationships matter.
Why Existing Stack Over New Tools?
Existing stack solved 80%. New tools solve 100% but cost 5x in time, money, and complexity.
Why Parent-Child Spans?
Mirrors how our application maintains state. One request → multiple factors → multiple LLM calls.
Startup Engineering Lessons:
Don’t: Add new tools before understanding the problem.
Do: Define what you need first (saved 3 weeks).
Don’t: Evaluate 5 tools when you don’t know what you need.
Do: Use existing stack, learn what’s missing, choose deliberately.
Don’t: Wait for the “perfect” solution.
Do: Ship an 80% solution in 5 days, iterate based on production issues.
We’ll eventually need specialized AI observability tools. But not today. Tomorrow, we’ll know exactly which tool solves which problem.
That’s Startup Engineering: choose the simple over the perfect solution. Solve for 80%. Iterate to 100%.